
저장소
[AtoI] Chapter 04. Sequence-to-Sequence 본문
01. Machine Translation 소개
(1) Objective

어떤 언어의 문장 x가 주어졌을 때 y로 가능한 집합 Y 중, 가장 확률이 높은 것을 ^y 이라고 한다.
번역의 궁극적인 목표는 이러한 ^y를 찾아내는 것이다.
(2) History
자연어 처리 분야의 역사에 대해 간략하게 살펴보자.
2014년 전까지는 자연어처리 분야는 큰 이슈가 없었지만 이후 NMT가 등장하면서 급속도로 변화를 맞이하게 된다.
현재 상용된 기계 번역 시스템에는 NMT가 주로 사용되고 있다.
(3) NMT가 성능이 좋은 이유
① End-to-end 모델
- SMT(Statistical Machine Translation, 통계 기반 기계 번역)은 여러가지 모듈로 구성된 구조였다. 이 때문에 여러 sub-module들이 진행될 수록 시스템의 복잡도가 증가하여 error 발생 빈도가 가중되었다. 하지만 NMT는 하나의 모델만으로 번역하여, 성능을 극대화했다.
② Better generlization
- Discrete한 단어를 continuous한 값으로 변환하여 계산
- 신경망 언어모델 기반 구조로 더욱 자연스러운 번역이 가능
③ LSTM과 Attention의 적용으로 Sequence의 길이에 구애받지 않고 번역(=RNN의 한계 극복)
02. Sequence to Sequence
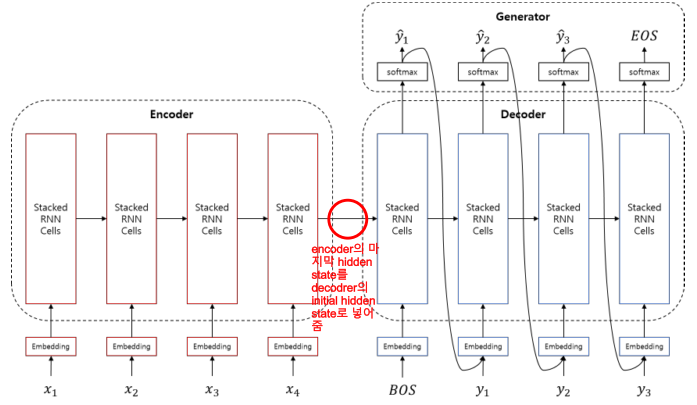
(1) Sequence to Sequnce의 3가지 서브 모듈
seq2seq의 3가지 모듈에는 Encoder, Decoder, Generator가 있다.
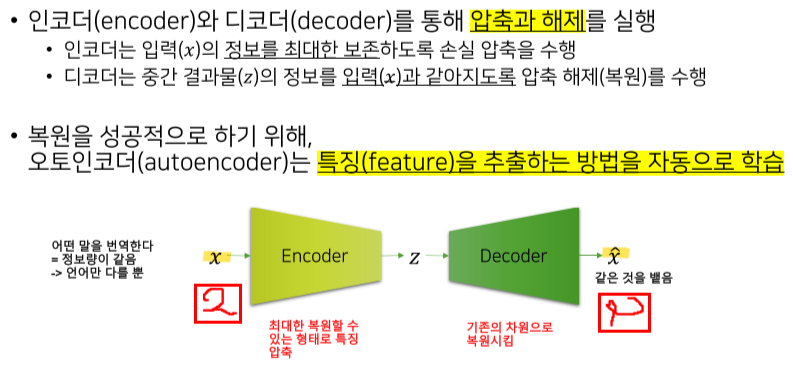
이때 Encoder는 입력 x를 받아 정보를 최대한 보존하여 압축을 수행하고, Decoder는 Encoder의 결과물을 받아 최대한 기존의 x와 같아지도록 압축 해제를 수행한다. 후반에 자세하게 살펴보도록 하자.
(2) seq2seq 모델 수식화
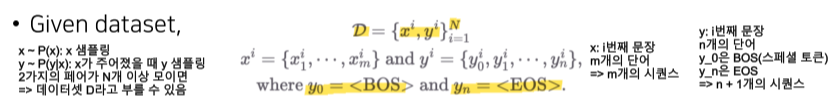
먼저 데이터셋 D를 살펴보면, 우선 {x, y}의 쌍이 N개 주어진다.
이때 xi는 m개의 단어로 이루어진 i번째 문장, yi는 n+1개의 단어로 이루어진 i번째 문장이다.
y_0는 BOS(입력의 시작), y_n은 EOS(입력의 끝)라는 스페셜 토큰이다.
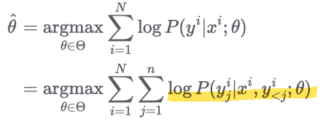
likelihood를 maximize하는 파라미터를 찾는 과정이다.
m개의 단어로 구성된 문장을 넣었을 때 n개의 단어로 이루어진 문장을 뱉어내는 함수의 파라미터는 최대우도법(MLE)를 사용하여 찾을 수 있다. log-likelihood function의 최대값을 추정하는 수식이다.
(cf. 찾고자 하는 파라미터 θ에 대하여 편미분하고 그 값이 0이 되도록 하는 를 찾는 과정을 통해 likelihood 함수를 최대화 시켜줄 수 있는 θ를 찾을 수 있다.)
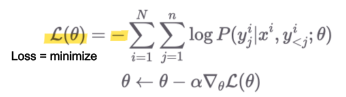
이후 loss를 minimize하기 위해 θ로 미분한 것의 gradient를 구하고, gradient descent를 θ에 수렴할 때 까지 반복한뒤 음수 기호(-)를 붙여준다.
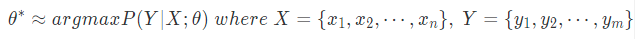
seq2seq 모델을 이용한 작업을 간단하게 한줄로 수식화한 모습이다.
(모델 파라미터가 주어졌을 때 source 문장 x를 받아서 target 문장 Y를 반환할 확률을 최대로 하는 모델 파라미터를 학습하는 과정)
(3) Review: Autoencoders
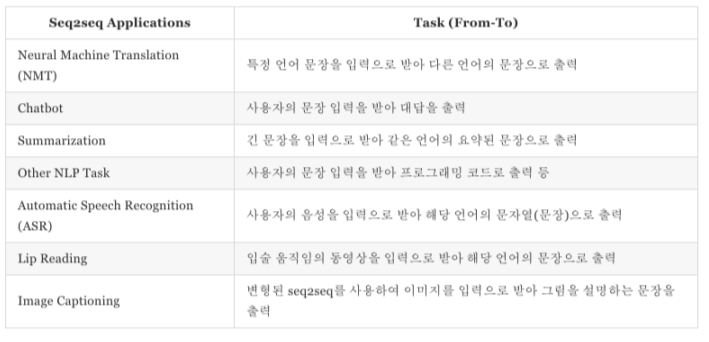
(4) Applications
03. Encoder
(1) 역할
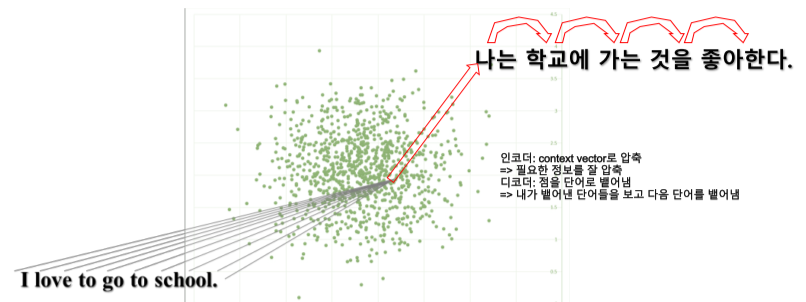
인코더는 source 문장을 입력으로 받아 문장을 압축하여 vector를 만들어 낸다.
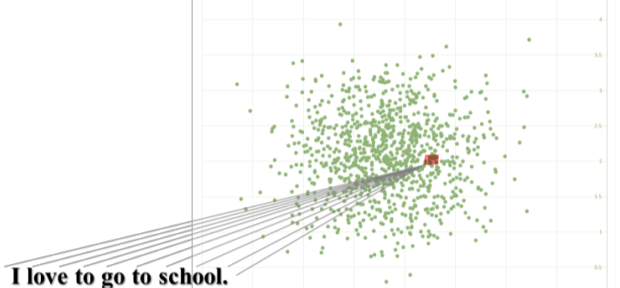
주어진 문장을 벡터화하여 높은 차원에 존재하는 데이터를 낮은 차원의 어떤 한 점으로 projection 시키는 작업이라고 할 수 있다.
(2) 수식
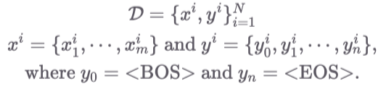
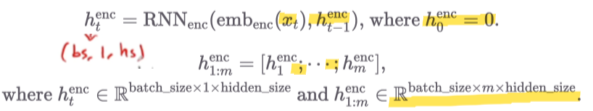

(3) 정리

04. Decoder
(1) 역할
디코더는 인코더로부터 받은 Context Vector와 함께 <BOS> 토큰(Beigining of Sentence)을 입력으로 받는다.
이후 Generator로부터 생성되는 문자를 생성하고 다음 Hidden state layer에 입력으로 전달한다.
최종적으로 <EOS> 토큰(End of Sentence)이 나올 때까지 동작한다.
(2) 수식

decoder 입력의 초기값인 y_0에 <BOS>를 넣어주는 것이 특징이다.
Decoder의 시작부분 같은 경우에는 context vector와 임의의 초기값으로 설정한 이전 state의 출력 값과 이전 state의 hidden vector값이 입력되어 첫 출력 값을 도출한다.
이후 이제까지 번역한 단어들과 encoder의 결과에 기반하여 현재 time-step의 단어를 유추해내는 작업을 수행한다.
(3) 정리

05. Generator
(1) 역할
디코더에서 vector를 받아 softmax를 계산(0 ~ 1 사이의 확률 값)하고 최고 확률을 가진 단어를 선택하는 모듈이다.
(cf. 디코더의 Hidden state를 받아 현재 time-step의 출력 토큰에 대한 확률 분포를 반환한다. 이때 확률 분포상 가장 확률이 높은 단어를 선택한다.)
(2) 수식

이때 y_n의 토큰은 계산의 종료를 나타낸다.

time-step 별로 가장 확률이 높은 단어를 선택하는 분류 작업이므로, cross entropy를 손실 함수로 사용한다.
더불어 perplexity를 통해 번역 모델의 성능을 나타낼 수 있다.
(3) 정리

'IT > 인공지능' 카테고리의 다른 글
| [추천시스템] 02. 추천 알고리즘_컨텐츠기반 (0) | 2022.04.12 |
|---|---|
| [추천시스템] 01. 추천시스템 개요 (0) | 2022.04.05 |
